Einleitung
Retrieval-Augmented Generation (RAG) ist eines der vielversprechendsten Muster für den Aufbau domänenspezifischer KI-Assistenten. Anstatt sich ausschliesslich auf das allgemeine Wissen eines Large Language Models (LLM) zu verlassen, reichert RAG jede Anfrage mit relevantem Kontext aus einer kuratierten Wissensbasis an.
Dieser Blogbeitrag beschreibt einen Proof of Concept (PoC), den wir entwickelt haben: einen LawBot – ein RAG-basierter Chatbot, der juristische Fragen auf Basis tatsächlicher Rechtstexte beantwortet.
Live ausprobieren unter https://lexchat.ch/
Warum RAG?
Large Language Models sind leistungsfähig, stossen aber bei domänenspezifischem, aktuellem oder vertraulichem Wissen an ihre Grenzen:
- Halluzinationen – LLMs können plausible, aber falsche Antworten generieren.
- Veraltetes Wissen – Die Trainingsdaten haben ein Stichtagsdatum.
- Kein Zugriff auf private Daten – Interne Dokumente sind nicht Teil des Trainingssets.
RAG begegnet diesen Herausforderungen, indem zur Abfragezeit relevante Dokumentenabschnitte abgerufen und als Kontext in den LLM-Prompt eingefügt werden.
Architekturübersicht
Der LawBot-PoC besteht aus folgenden Komponenten:
Embedding-Pipeline
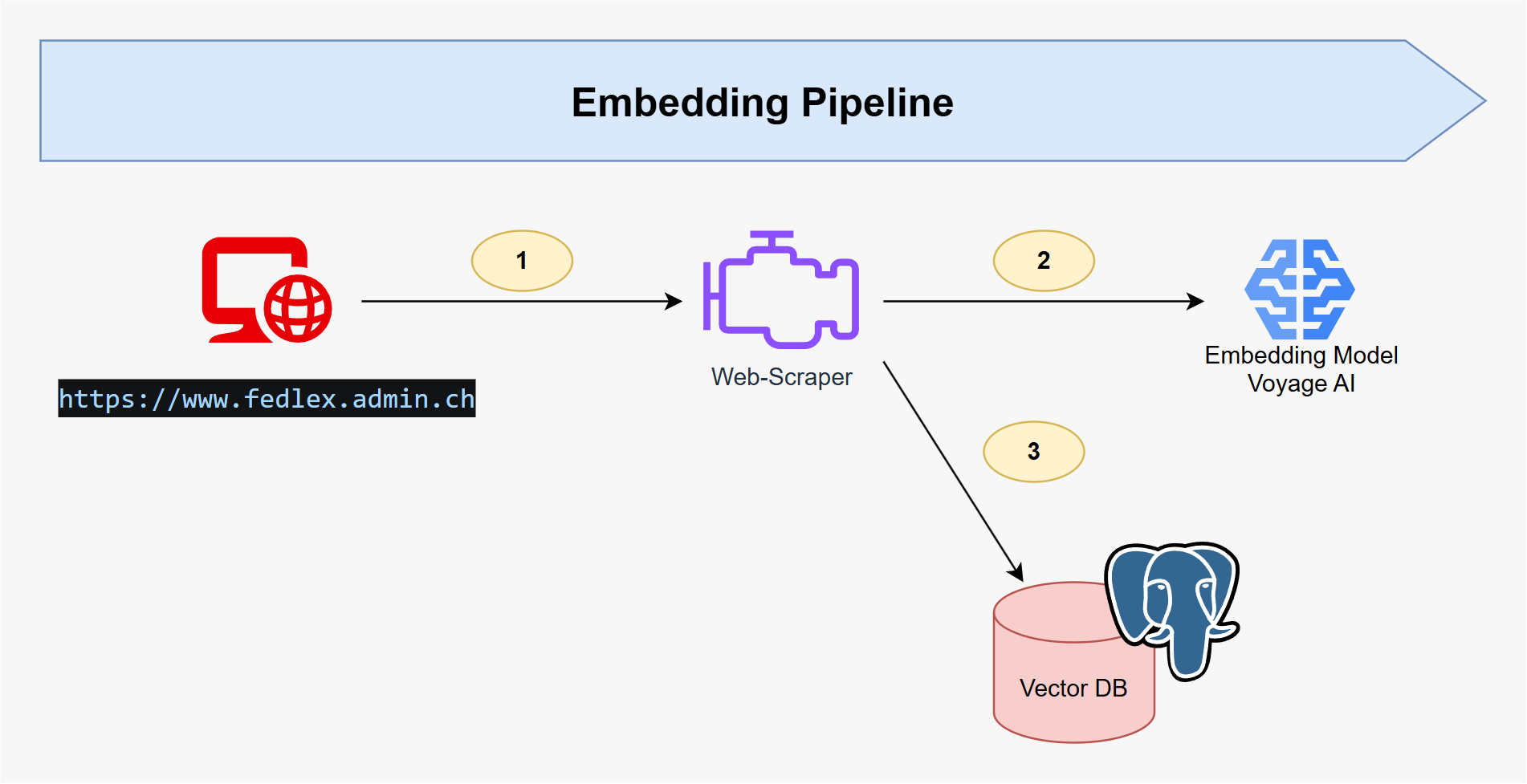
- Dokumentenaufnahme – Rechtsdokumente (z. B. Gesetze, Verordnungen, Verträge) werden geparst und in semantisch sinnvolle Abschnitte unterteilt.
- Embedding-Generierung – Jeder Abschnitt wird mit Voyage AI Embeddings vektorisiert, die für Retrieval-Aufgaben optimiert sind.
- Vektorspeicherung – Die resultierenden Embeddings werden in einer PostgreSQL-Datenbank mit aktivierter
pgvector-Erweiterung gespeichert.
Abfrage-Pipeline
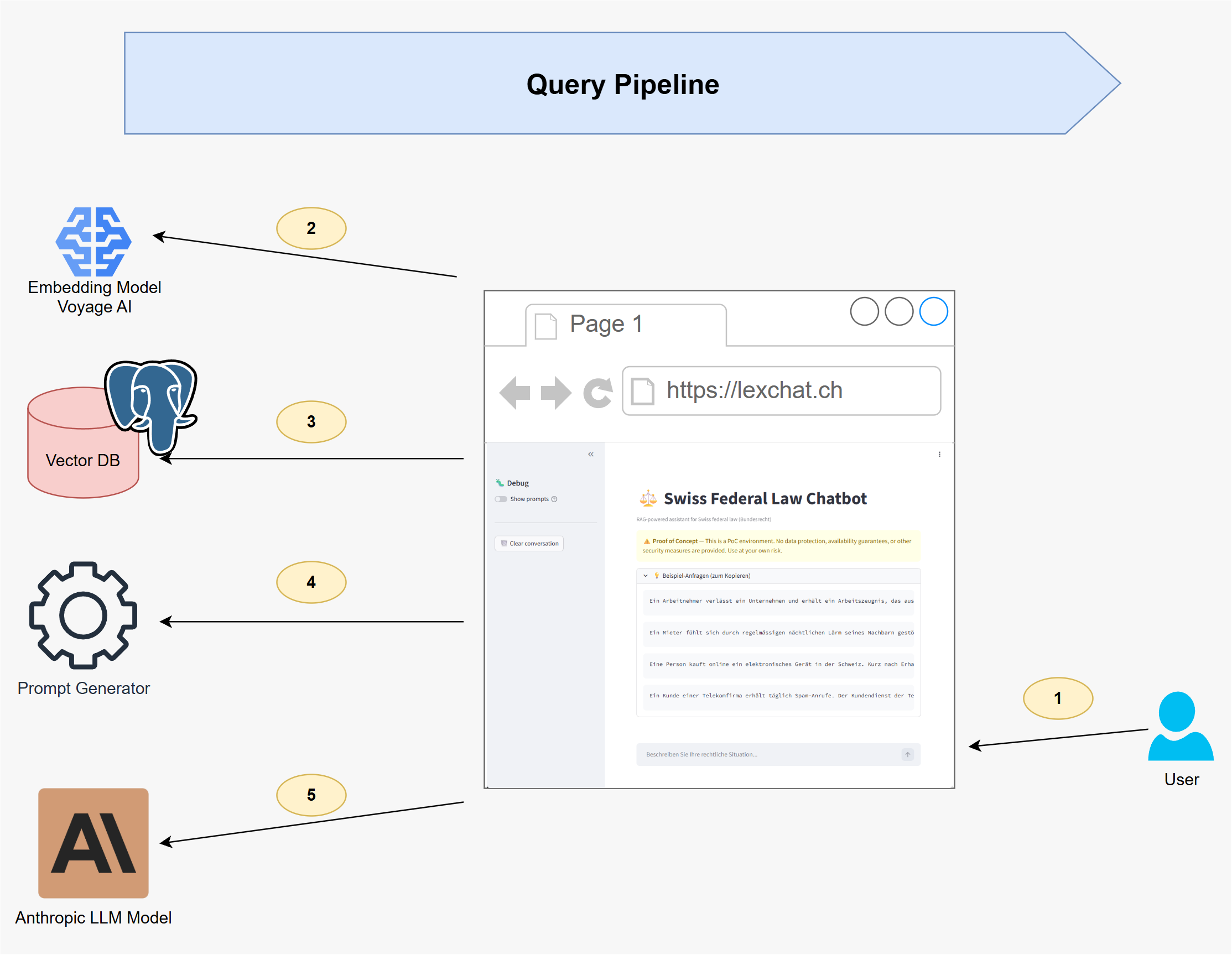
- Benutzeranfrage – Der Benutzer stellt eine juristische Frage über die Chat-Oberfläche.
- Abfrage-Embedding – Die Frage wird mit demselben Voyage AI-Modell vektorisiert.
- Ähnlichkeitssuche – Die relevantesten Dokumentenabschnitte werden per Vektor-Ähnlichkeitssuche aus PostgreSQL abgerufen.
- Prompt-Generierung – Die abgerufenen Abschnitte werden zu einem strukturierten Prompt zusammengestellt, der die Benutzerfrage mit dem relevanten Kontext kombiniert.
- Antwortgenerierung – Der Prompt wird an Anthropic Claude gesendet, das eine fundierte, referenzierte Antwort generiert.
Technologie-Stack
Der PoC nutzt eine gezielte Auswahl an Technologien, die für ihre Stärken in RAG-Workflows ausgewählt wurden:
| Komponente | Technologie |
|---|---|
| LLM | Anthropic Claude Opus 4.6 |
| Embeddings | Voyage AI voyage-3-large |
| Vektorspeicher | PostgreSQL + pgvector |
| Sprache | Python |
Wichtigste Erkenntnisse
- Voyage AI Embeddings liefern eine hohe Retrieval-Qualität, insbesondere bei domänenspezifischen Texten, und bieten ein gutes Verhältnis zwischen Kosten und Leistung.
- PostgreSQL mit pgvector ist eine pragmatische Wahl – es wird keine dedizierte Vektordatenbank benötigt, wenn bereits Postgres im Einsatz ist.
- Anthropic Claude überzeugt durch gut strukturierte, differenzierte Antworten und die Fähigkeit, Quellen aus dem bereitgestellten Kontext zu zitieren.
- Die Chunking-Strategie ist entscheidend – Die Qualität des Retrievals hängt stark davon ab, wie Dokumente aufgeteilt werden. Semantisches Chunking übertraf in unseren Tests naives Splitting mit fester Grösse.
Ausblick
Dieser PoC legt den Grundstein für einen produktionsreifen juristischen Assistenten. Mögliche nächste Schritte umfassen:
- Hybride Suche – Kombination von Vektor-Ähnlichkeit mit schlüsselwortbasiertem (BM25) Retrieval für besseren Recall.
- Reranking – Hinzufügen eines Cross-Encoder-Reranking-Schritts zur Verbesserung der Precision.
- Feedback-Schleife – Benutzern ermöglichen, Antworten zu bewerten, um die Retrieval-Qualität kontinuierlich zu verbessern.
Weitere Updates folgen, wenn wir den LawBot vom PoC zur Produktionsreife weiterentwickeln.