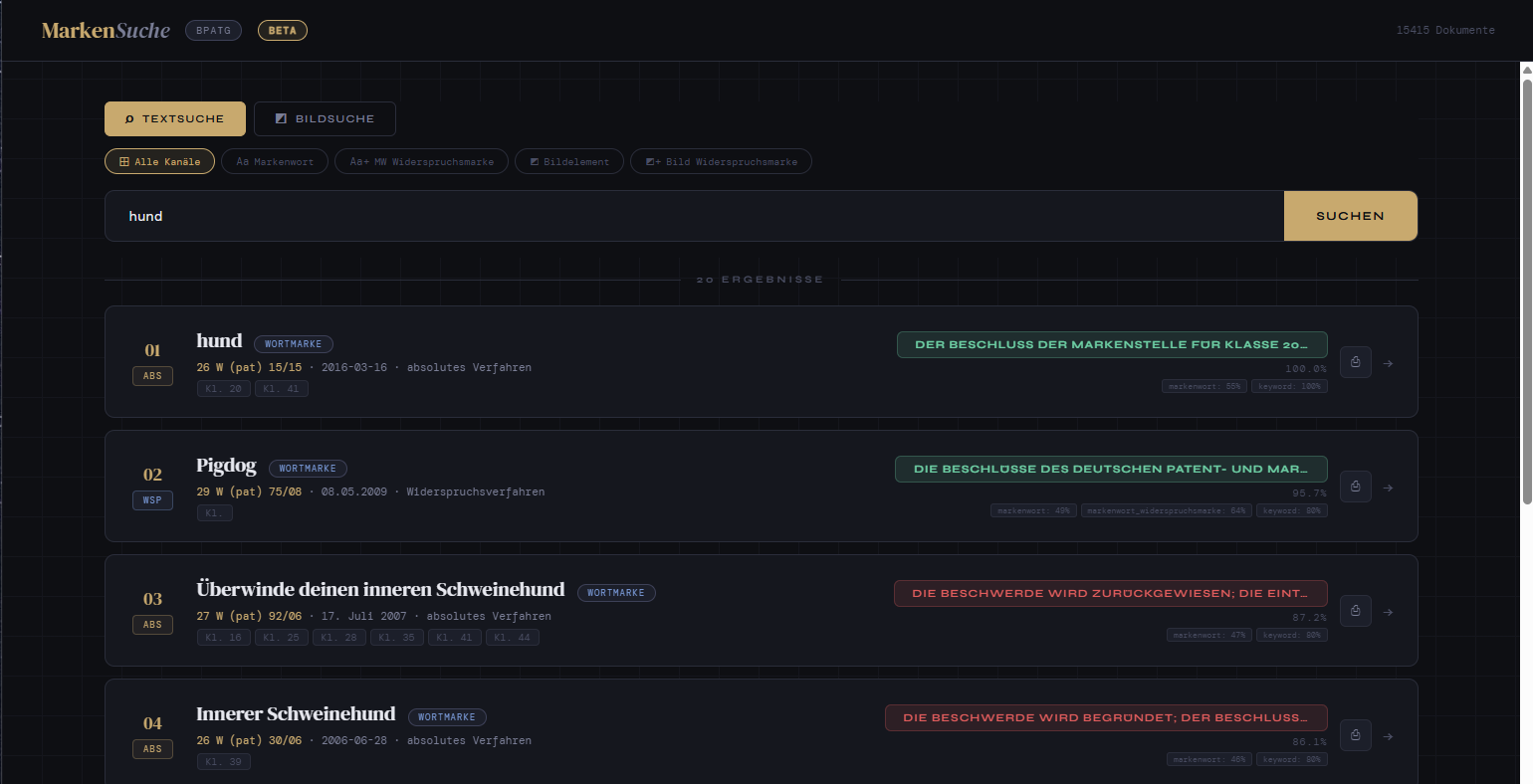
Einleitung
Die meisten Retrieval-Systeme in Produktion sind heute rein textbasiert. Dokumente werden geparst, in Chunks aufgeteilt, eingebettet und abgerufen. Das funktioniert gut – bis der Korpus Dokumente enthält, in denen der visuelle Inhalt ebenso viel Bedeutung trägt wie der Text.
Deutsche Markenentscheide sind genau ein solcher Korpus. Bei der Beurteilung, ob zwei Bildmarken verwechslungsfähig sind, handelt es sich nicht wirklich um ein Textproblem – es geht um Logos, Schriftarten, Farbschemata und visuelle Komposition.
Dieser Blogbeitrag beschreibt einen Proof of Concept (PoC), den wir entwickelt haben: eine multimodale Suchmaschine über 15'000 Markenentscheide des Bundespatentgerichts, die strukturierte JSON-Extraktion mit seitenbasierten Bild-Embeddings kombiniert, um sowohl über die rechtliche Begründung als auch über die visuellen Marken selbst zu suchen.
Warum multimodal?
Klassische, rein textbasierte Suche versagt bei diesem Korpus aus mehreren spezifischen Gründen:
- Bildmarken sind Bilder, kein Text. Ein Entscheid darüber, ob das Logo von Unternehmen A das Logo von Unternehmen B verletzt, enthält die tatsächlichen Logos als eingebettete Bilder. Sie zu ignorieren verwirft den Kern des Falls.
- Layout trägt semantische Information. Gegenüberstellungen konkurrierender Marken, Klassifikationstabellen (Nizza-Klassifikation) und Unterschriftsblöcke kodieren Bedeutung durch ihre räumliche Anordnung.
- Juristische Metadaten sind hochstrukturiert. Jeder Entscheid hat ein Aktenzeichen, einen Senat, ein Datum, eine Liste zitierter Normen und eine Liste von Nizza-Klassen. Diese als Freitext zu behandeln verschenkt viel Retrieval-Signal.
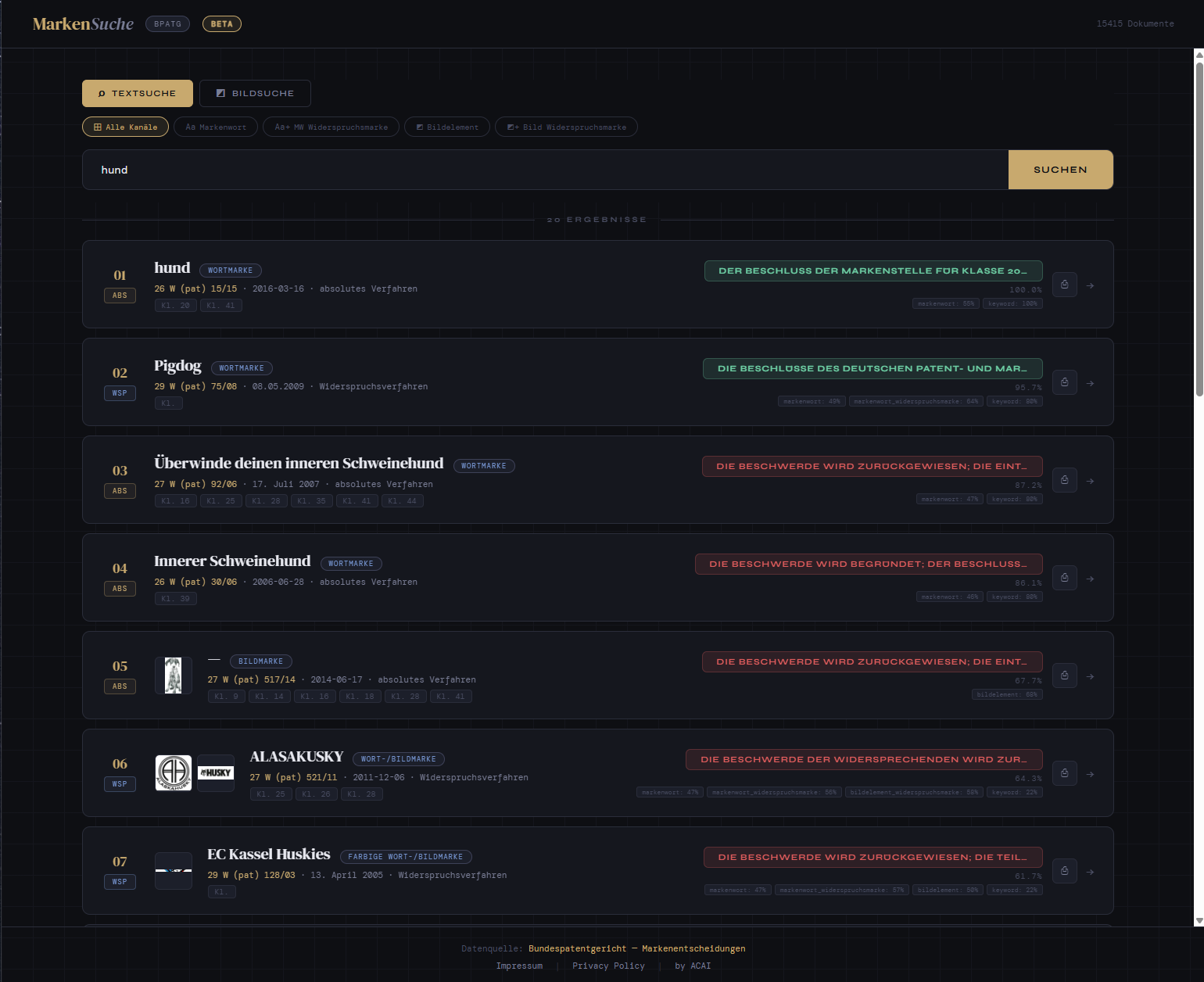
- Nutzer wollen über all das gleichzeitig suchen. “Finde Entscheide, in denen ein stilisiertes Tierlogo für Bekleidung in Klasse 25 zurückgewiesen wurde” erfordert sowohl ein visuelles Konzept (Tierlogo) als auch strukturierte Filter (Klasse 25, Zurückweisung).
Eine reine Text-Pipeline kann nichts davon gut beantworten. Daher haben wir zwei parallele Embedding-Tracks aufgebaut – einen für strukturierten Text, einen für Seitenbilder – und stellen sie über separate, zweckgebundene Suchmodi bereit.
Der Korpus
Der PoC nutzt die öffentlich verfügbaren Markenentscheide (“Marken-Beschwerden”) aus der Entscheidungsdatenbank des Bundespatentgerichts – rund 15'000 PDF-Entscheide der Marken-Beschwerdesenate (24., 25., 26., 27., 28., 29., 30., 32., 33. Senat). Jedes PDF ist ein gescanntes oder nativ erzeugtes Dokument mit:
- Der Begründung des Gerichts in deutscher Rechtssprache
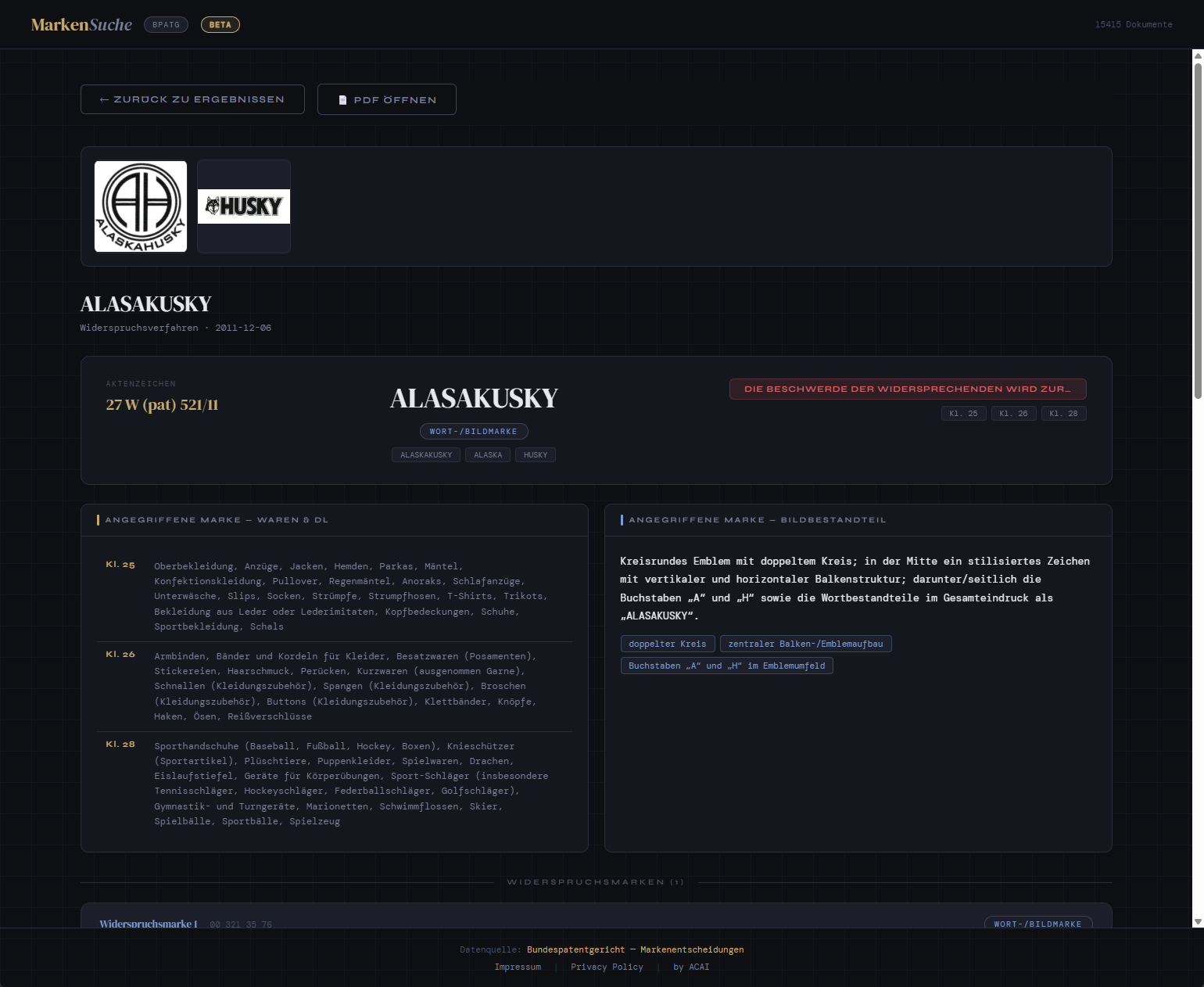
- Der/den streitgegenständlichen Marke(n), oft als eingebettete(s) Bild(er)
- Klassifikations-Metadaten (Nizza-Klassen, Waren- und Dienstleistungsverzeichnisse)
- Verweisen auf frühere Rechtsprechung und Gesetzesnormen
Ein perfektes Testfeld: gross genug für echte Retrieval-Infrastruktur, strukturiert genug um von Extraktion zu profitieren, und visuell genug, dass das Ignorieren der Bilder den Zweck verfehlen würde.
Architekturüberblick
Das System hat zwei parallele Embedding-Tracks bei der Ingestion und separate Suchmodi zur Abfragezeit.
Embedding-Pipeline
Für jedes PDF im Korpus laufen zwei unabhängige Extraktionspfade:
Track 1: Strukturierte JSON-Extraktion
- Dokumenten-Parsing – Das PDF wird in Seiten aufgeteilt und die Textebene extrahiert (mit OCR-Fallback für gescannte Seiten).
- LLM-basierte strukturierte Extraktion – Ein visionsfähiges LLM liest jeden Entscheid und erzeugt ein JSON-Objekt nach einem festen Schema: Aktenzeichen, Senat, Entscheidungsdatum, Entscheidungstyp (Zurückweisung / Eintragung / teilweise), die streitgegenständlichen Marken (Wortmarken, Bildmarkenbeschreibungen), Nizza-Klassen, zitierte Normen, Zusammenfassung der rechtlichen Begründung und das Ergebnis.
- Kanalspezifische Text-Builder – Anstatt rohes JSON einzubetten, werden die extrahierten Daten in zweckgebundene Textrepräsentationen pro Retrieval-Kanal transformiert (z.B. einer fokussiert auf Wortmarken, ein anderer auf Bildmarken-Beschreibungen). Jeder Kanal-Text-Builder komponiert einen natürlichsprachlichen Absatz aus den relevanten Feldern, optimiert für das, was dieser Kanal finden muss.
- Text-Embedding – Jeder Kanaltext wird mit Voyage AI
voyage-3-largeeingebettet, das mehrsprachig ist und mit deutscher Rechtssprache gut umgeht. Mehrere Embedding-Vektoren pro Dokument (einer pro Kanal) werden zusammen gespeichert.
Track 2: Seitenbild-Embedding
- Seiten-Rasterisierung – Jede PDF-Seite wird als hochauflösendes Bild gerendert.
- Vision-Embedding – Jedes Seitenbild wird mit Voyage AI
voyage-multimodal-3eingebettet, einem dedizierten multimodalen Embedding-Modell, das Bilder in einen mit Text abfragbaren Vektorraum abbildet. - Vektorspeicherung – Bild-Embeddings werden als zusätzliche Spalte auf derselben Dokumentzeile gespeichert, neben den Text-Kanal-Embeddings.
Beide Tracks schreiben in eine einzelne PostgreSQL-Datenbank mit pgvector. Jede Dokumentzeile in der Haupttabelle trägt mehrere Embedding-Spalten (eine pro Text-Kanal plus eine für den Bild-Track), zusammen mit dem vollständigen extrahierten JSON und den Metadaten.
Abfrage-Pipeline
Zur Abfragezeit bietet das System separate Suchmodi – textbasiert und bildbasiert – die jeweils für ihren Anwendungsfall optimiert sind:
Textsuche (Ein-Kanal oder Multi-Kanal):
- Query-Embedding – Die Suchanfrage des Nutzers wird einmal mit
voyage-3-largeeingebettet. - Multi-Kanal-Vektorsuche – Der Query-Vektor wird gegen jede angeforderte Text-Kanal-Embedding-Spalte per Kosinusähnlichkeit abgeglichen. Nutzer können Kanäle gewichten (z.B. Wortmarken-Ähnlichkeit vs. rechtliche Begründung betonen).
- Gewichtete Score-Kombination – Pro-Kanal-Ähnlichkeitswerte werden mittels gewichtetem Durchschnitt kombiniert, was einen einzelnen Relevanzwert pro Dokument ergibt.
- Keyword-Hybrid-Boost – Ein paralleler Keyword-Pfad nutzt
ILIKEund PostgreSQLpg_trgmTrigramm-Ähnlichkeit, um exakte Treffer einzuspeisen, die reine Vektorsuche übersehen könnte, und um Dokumente zu boosten, die die Suchbegriffe wörtlich enthalten.
Bildsuche:
- Bild-Embedding – Ein hochgeladenes Bild (z.B. ein Logo) wird mit
voyage-multimodal-3eingebettet. - Visuelle Ähnlichkeitssuche – Der Bildvektor wird gegen die Bild-Embedding-Spalte abgeglichen, um visuell ähnliche Marken im gesamten Korpus zu finden.
Beide Modi liefern gerankte Ergebnisse mit Quellverweisen – relevante Entscheidungsseiten, extrahierte Metadaten und passende Textpassagen – anstatt eine synthetisierte Antwort zu generieren.
Tech Stack
| Komponente | Technologie |
|---|---|
| LLM (Extraktion) | OpenAI GPT-5.4-nano |
| Text-Embeddings | Voyage AI voyage-3-large (mehrsprachig) |
| Bild-Embeddings | Voyage AI voyage-multimodal-3 |
| Vektorspeicher | PostgreSQL + pgvector |
| Keyword-Suche | PostgreSQL pg_trgm (Trigramm-Ähnlichkeit) |
| PDF-Parsing | pymupdf |
| Backend | FastAPI + Uvicorn |
| Sprache | Python |
Wichtigste Erkenntnisse
- Zwei Tracks schlagen einen. Strukturierte Text-Kanäle liefern Präzision und Erklärbarkeit; Seitenbilder liefern Recall auf alles Visuelle, was die Extraktion übersehen hat. Jeder deckt die blinden Flecken des anderen ab.
- Kein rohes JSON einbetten. Embedding-Modelle sind auf Prosa trainiert, nicht auf geschweifte Klammern. Kanalspezifische Text-Builder, die natürlichsprachliche Absätze aus extrahierten Feldern komponieren, übertrafen konsistent das Einbetten von rohem JSON oder einfachen Key-Value-Dumps.
- Schema-Disziplin ist entscheidend. Wenn das Extraktionsschema über Dokumente hinweg driftet, sinkt die nachgelagerte Retrieval-Qualität spürbar. Ein striktes Schema mit
nullfür fehlende Felder schlägt ein permissives. - Mehrere Embedding-Kanäle pro Dokument erhöhen die Flexibilität. Die Trennung von Wortmarken-Text und Bildmarken-Beschreibungen in eigene Kanäle erlaubt es Nutzern zu gewichten, was für ihre Anfrage relevant ist. Ein einzelnes monolithisches Embedding pro Dokument verliert diese Steuerungsmöglichkeit.
- Keyword-Hybridsuche ist für Rechtstexte essenziell. Reine Vektorsuche übersieht exakte Begriffsübereinstimmungen, die im Recht wichtig sind (Aktenzeichen, spezifische Markennamen). Die Kombination von Vektorähnlichkeit mit trigrammbasierter Keyword-Suche (
pg_trgm) fängt auf, was Embeddings allein übersehen. - Seitenebene-Granularität ist meist richtig für visuelle Suche. Feiner zu gehen (Regionen, Abbildungen) erhöht die Komplexität ohne Mehrwert bei diesem Korpus; gröber zu gehen (ganzes Dokument) verliert die Fähigkeit, auf die spezifische Seite mit der streitgegenständlichen Marke zu verweisen.
- Gewichtete Score-Kombination ist einfach und effektiv. Für Multi-Kanal-Retrieval ist ein gewichteter Durchschnitt über Pro-Kanal-Kosinusähnlichkeiten einfach zu tunen und nachzuvollziehen – Nutzer können Kanalgewichte anpassen, um den Schwerpunkt zwischen Wortmarken, Bildelementen und rechtlicher Begründung zu verschieben.
Ausblick
Dieser PoC zeigt, dass multimodale Suche auf einem realen juristischen Korpus machbar und nützlich ist. Natürliche nächste Schritte:
- Strukturierte Metadaten-Filterung. SQL-
WHERE-Klausel-Vorfilter auf Senat, Nizza-Klasse, Datumsbereich und Ergebnis vor der Vektorsuche würden den Noise für gezielte Anfragen dramatisch reduzieren. - Cross-modale Fusion. Text- und Bildergebnisse in einer einzigen gerankten Liste zusammenführen (z.B. via Reciprocal Rank Fusion) statt separate Suchmodi anzubieten, würde Nutzern ein einheitliches Erlebnis bieten.
- Reranking. Ein Cross-Encoder-Reranker auf dem fusionierten Kandidatenset könnte die Präzision an der Spitze der Ergebnisliste verbessern.
- Active Learning bei Extraktionsfehlern. Wenn Nutzer ein falsches Ergebnis melden, ermöglicht die Rückverfolgung, ob der Fehler bei der Extraktion oder beim Retrieval lag, gezielte Re-Extraktion der relevanten Dokumente.
- Dokumentübergreifendes Reasoning. Über das Auffinden einzelner Entscheide hinaus aufzeigen, wie sich eine Argumentationslinie über Senate und Jahre hinweg entwickelt hat.
Die Kombination aus strukturierter Extraktion und Seitenbild-Embedding ist unserer Erfahrung nach das robusteste Fundament für die Suche über visuell reiche, semi-strukturierte Dokumente – und das Markenrecht ist ein nahezu ideales Showcase dafür.