Intro
Retrieval-Augmented Generation (RAG) is one of the most promising patterns for building domain-specific AI assistants. Instead of relying solely on the general knowledge baked into a large language model, RAG enriches every query with relevant context retrieved from a curated knowledge base.
This blog post walks through a proof of concept (PoC) we built: a LawBot – a RAG-based chatbot designed to answer legal questions grounded in actual legal documents.
Check it out live at https://lexchat.ch/
Why RAG?
Large Language Models (LLMs) are powerful, but they have limitations when it comes to domain-specific, up-to-date, or confidential knowledge:
- Hallucination – LLMs can generate plausible but incorrect answers.
- Stale knowledge – Training data has a cutoff date.
- No access to private data – Internal documents are not part of the model’s training set.
RAG addresses these challenges by retrieving relevant document chunks at query time and injecting them into the LLM prompt as context.
Architecture Overview
The LawBot PoC is composed of the following components:
Embedding Pipeline
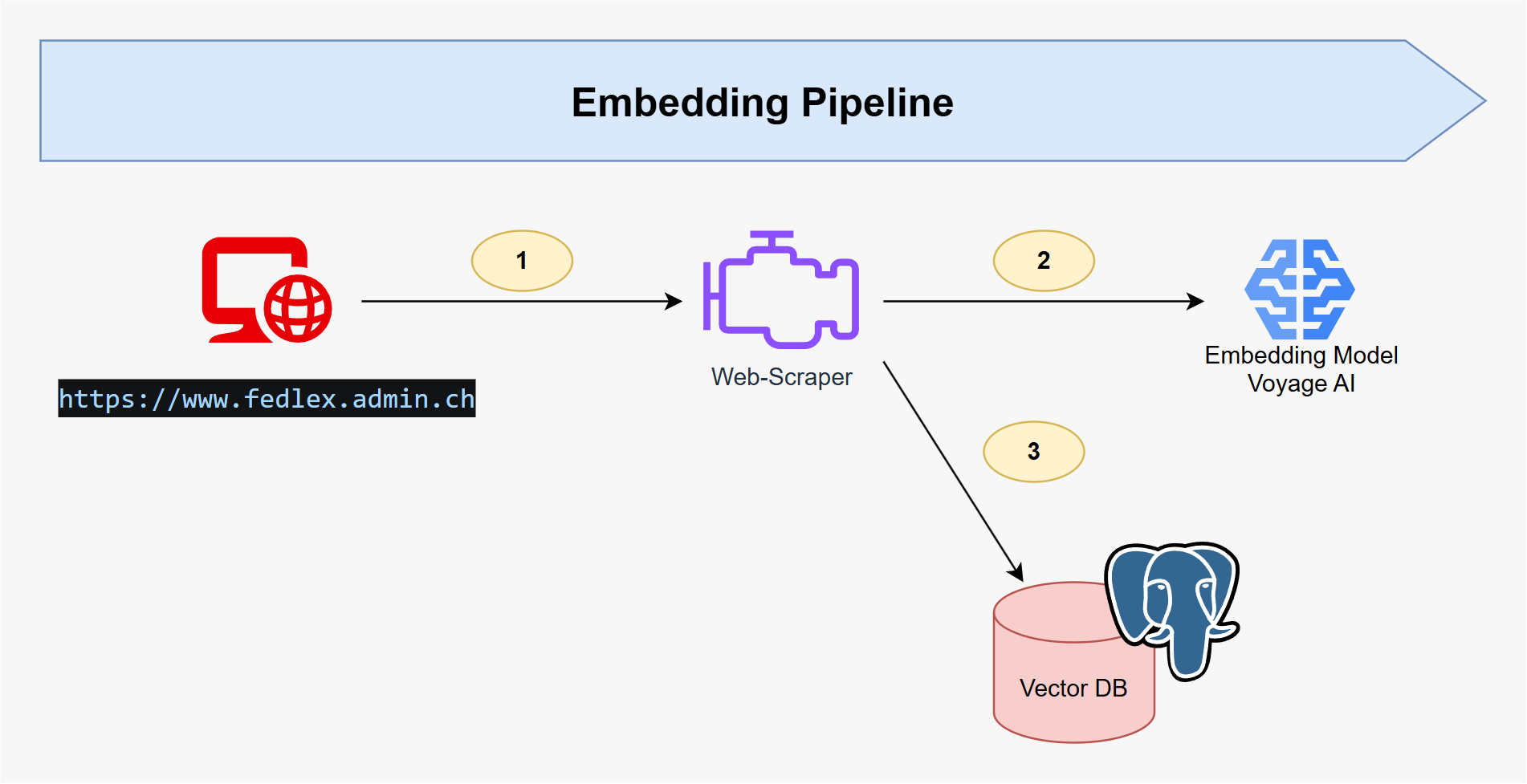
- Document Ingestion – Legal documents (e.g., laws, regulations, contracts) are parsed and split into semantically meaningful chunks.
- Embedding Generation – Each chunk is embedded using Voyage AI embeddings, which are optimized for retrieval tasks.
- Vector Storage – The resulting embeddings are stored in a PostgreSQL database with the
pgvectorextension enabled.
Query Pipeline
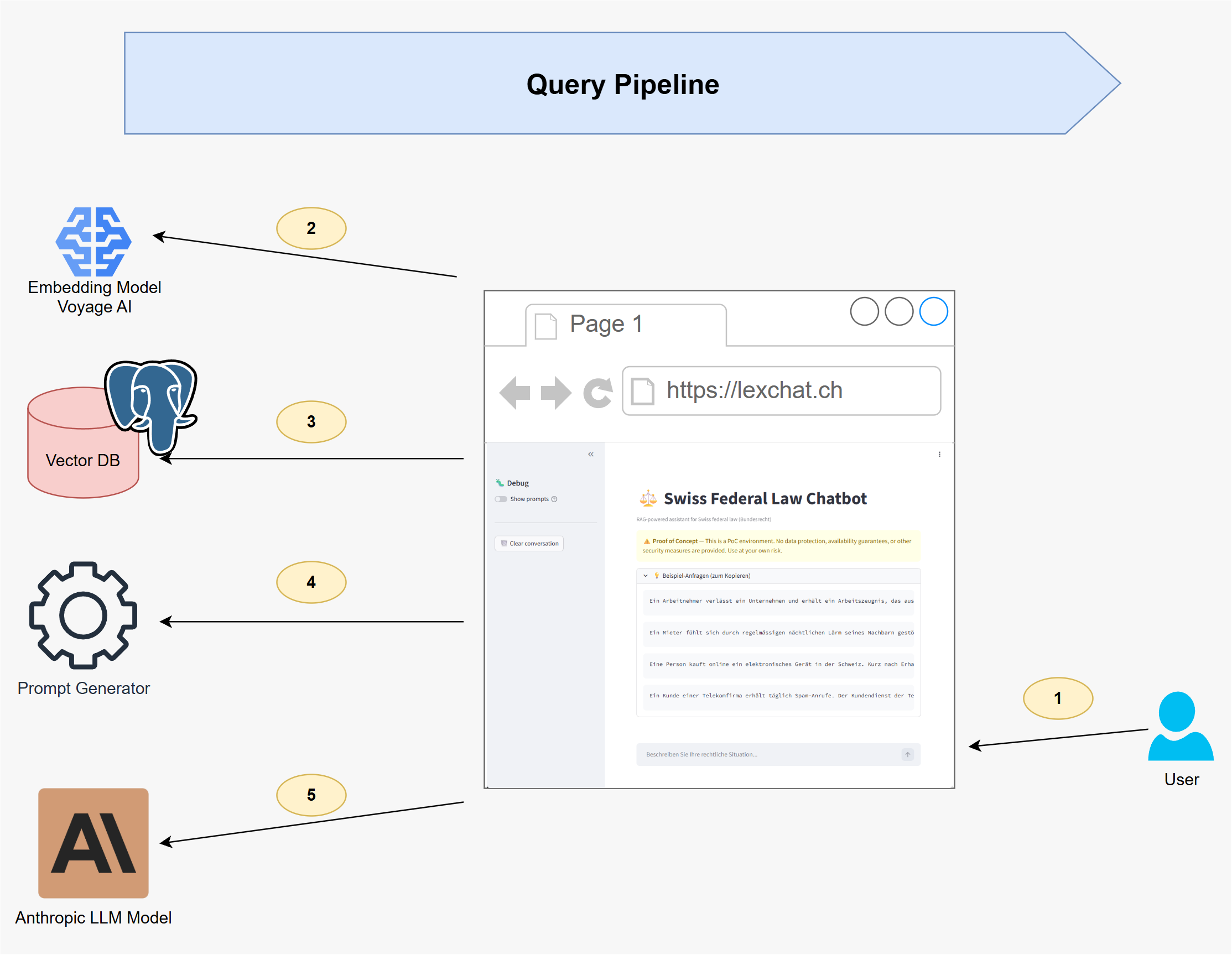
- User Query – The user asks a legal question via the chat interface.
- Query Embedding – The question is embedded using the same Voyage AI model.
- Similarity Search – The most relevant document chunks are retrieved from PostgreSQL via vector similarity search.
- Prompt Generation – The retrieved chunks are assembled into a structured prompt, combining the user’s question with the relevant context.
- Answer Generation – The prompt is sent to Anthropic Claude, which generates a grounded, referenced answer.
Tech Stack
The PoC leverages a focused set of technologies, chosen for their strength in retrieval-augmented generation workflows:
| Component | Technology |
|---|---|
| LLM | Anthropic Claude Opus 4.6 |
| Embeddings | Voyage AI voyage-3-large |
| Vector Store | PostgreSQL + pgvector |
| Language | Python |
Key Takeaways
- Voyage AI embeddings deliver strong retrieval quality, especially for domain-specific text, and offer a good balance between cost and performance.
- PostgreSQL with pgvector is a pragmatic choice – no need for a dedicated vector database when you already run Postgres.
- Anthropic Claude excels at generating well-structured, nuanced answers and following instructions to cite sources from the provided context.
- Chunking strategy matters – The quality of retrieval depends heavily on how documents are split. Semantic chunking outperformed naive fixed-size splitting in our tests.
Outlook
This PoC lays the groundwork for a production-ready legal assistant. Potential next steps include:
- Hybrid search – Combining vector similarity with keyword-based (BM25) retrieval for improved recall.
- Reranking – Adding a cross-encoder reranking step to improve precision.
- Feedback loop – Allowing users to rate answers to continuously improve retrieval quality.
Stay tuned for updates as we evolve the LawBot from PoC to production.