Intro
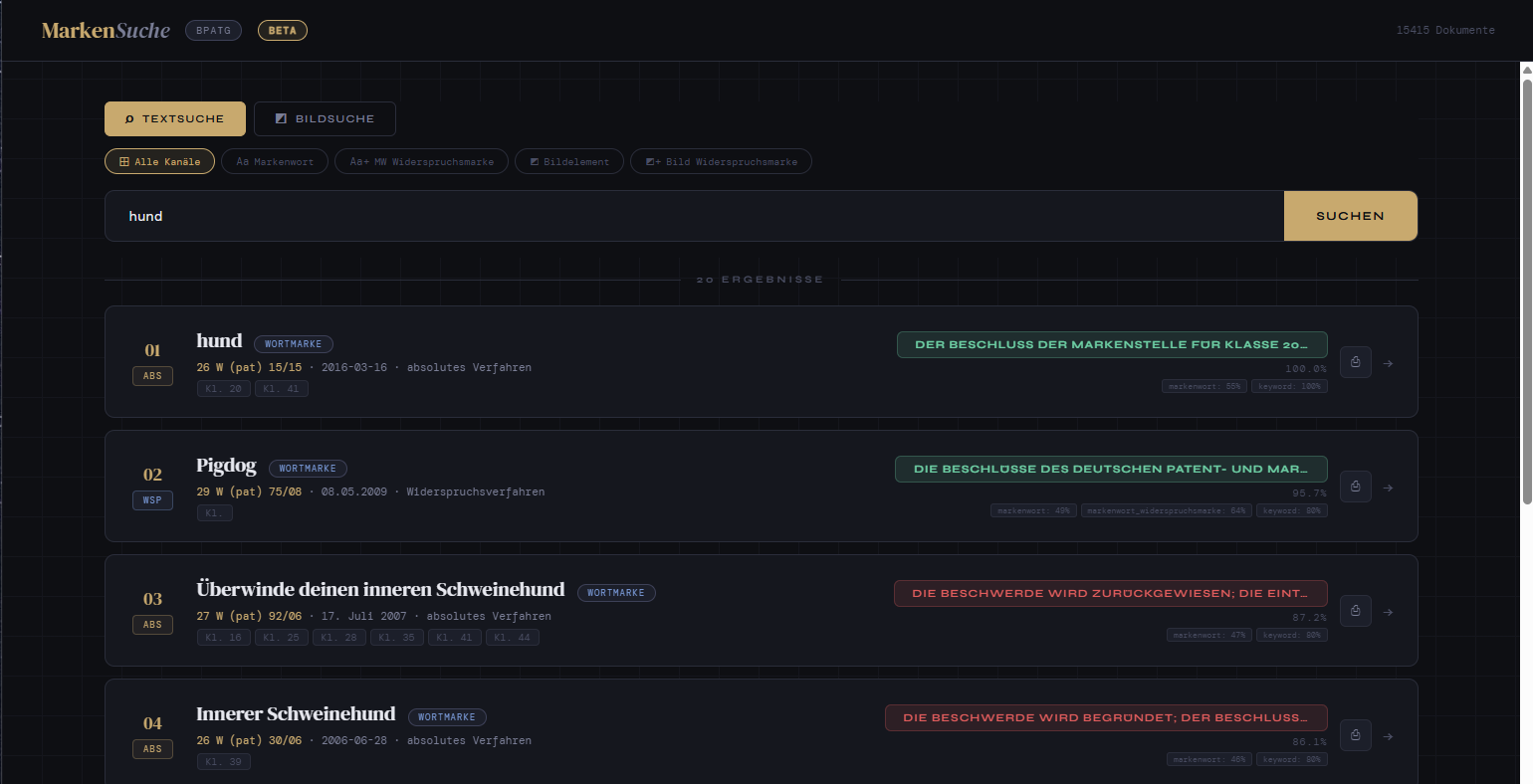
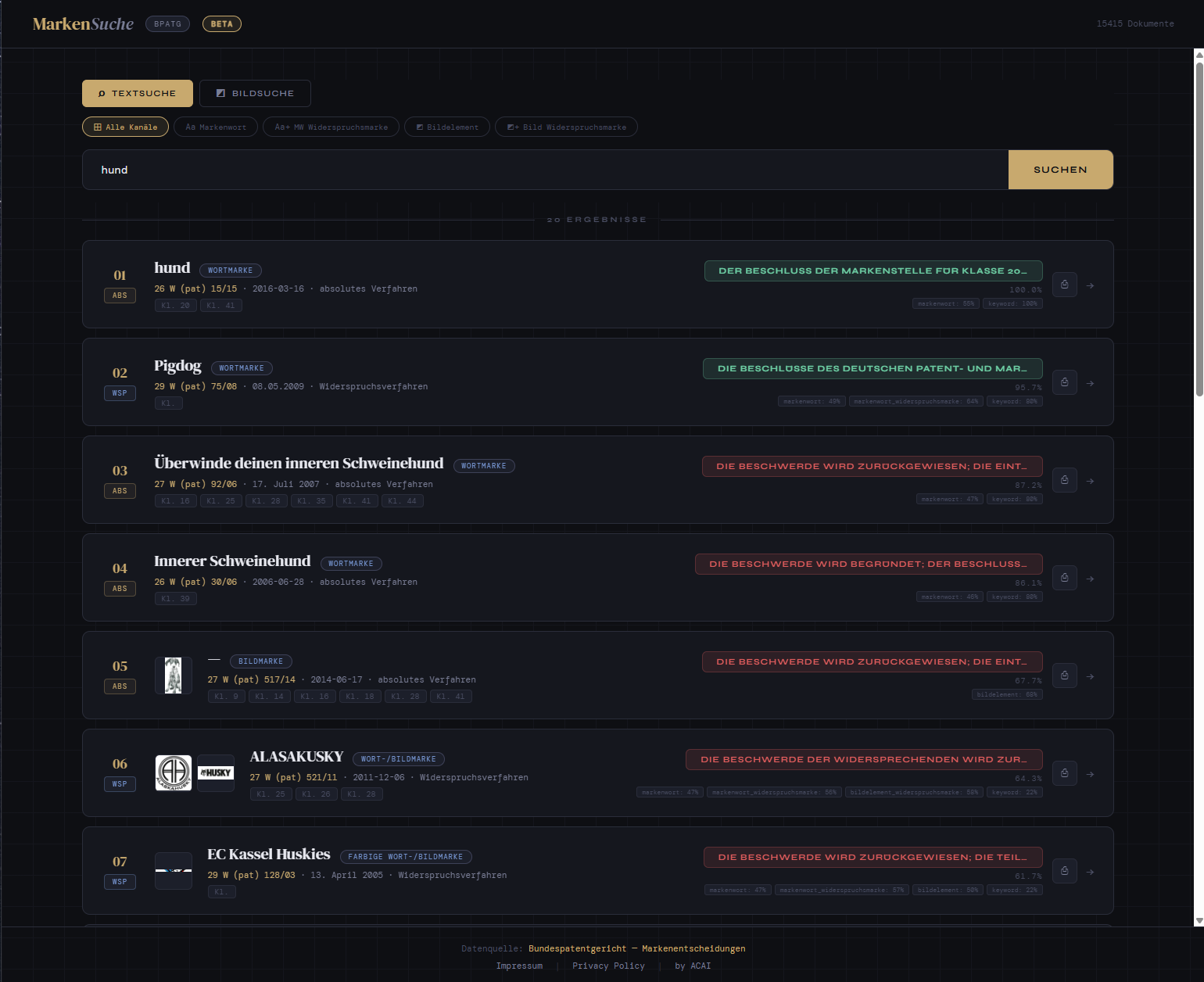
Most retrieval systems in production today are text-only. Documents are parsed, chunked, embedded, retrieved. That works well — until your corpus contains documents where the visual content carries as much meaning as the text.
German trademark decisions are exactly that kind of corpus. A ruling on whether two figurative marks are confusingly similar isn’t really a text problem — it’s a question about logos, fonts, color schemes, and visual composition.
This blog post walks through a proof of concept (PoC) we built: a multimodal search engine over 15,000 trademark decisions from the German Federal Patent Court (Bundespatentgericht), combining structured JSON extraction with page-level image embeddings to retrieve across both the legal reasoning and the visual marks themselves.
Why Multimodal?
Classical text-only retrieval breaks down on this corpus for a few specific reasons:
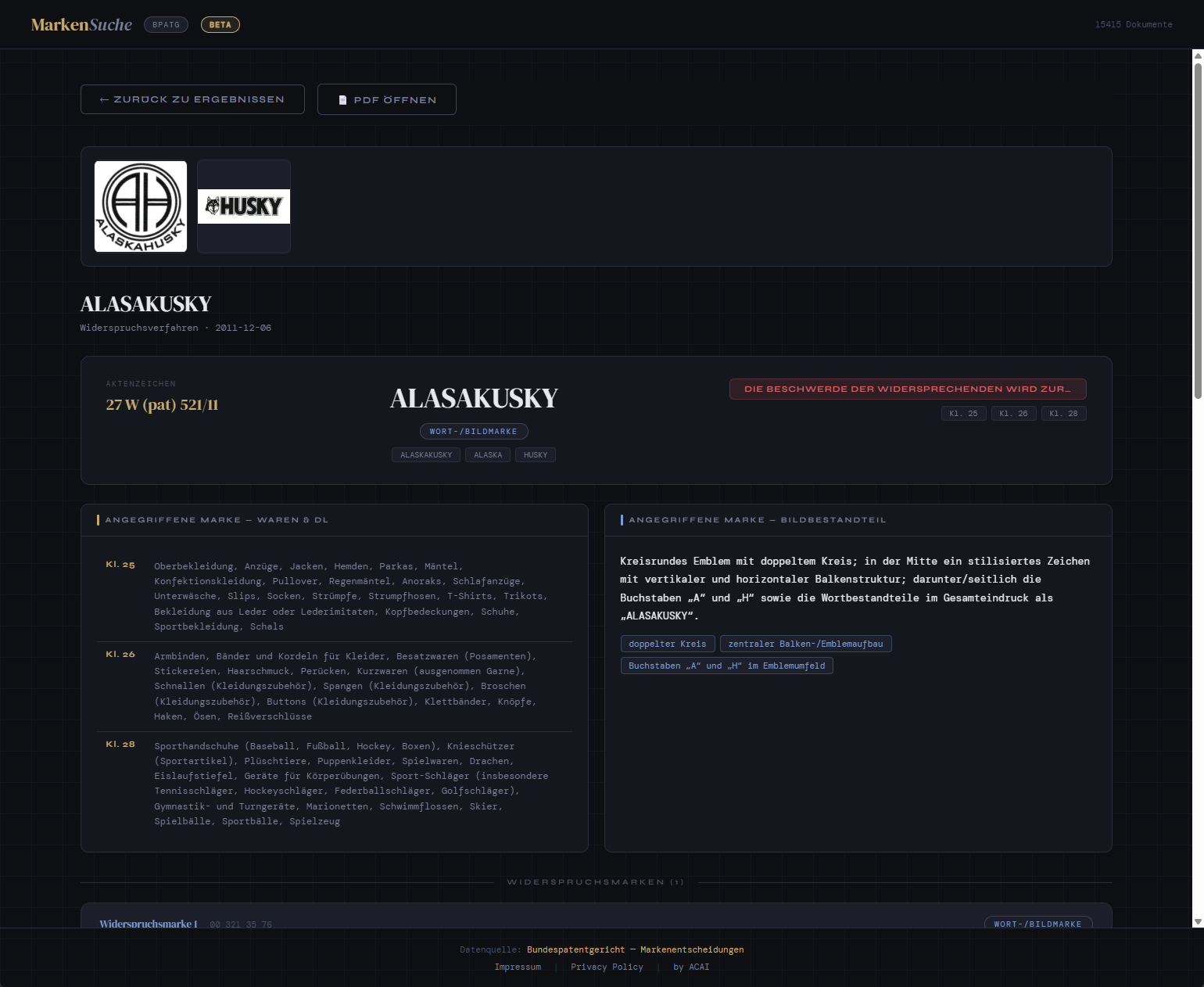
- Figurative marks are images, not text. A decision about whether the logo of company A infringes the logo of company B contains the actual logos as embedded images. Ignoring them throws away the heart of the case.
- Layout carries semantic information. Side-by-side comparisons of competing marks, classification tables (Nice classification), and signature blocks all encode meaning through their spatial arrangement.
- Legal metadata is highly structured. Every decision has a docket number (Aktenzeichen), a senate, a date, a list of cited norms, and a list of Nice classes. Treating these as free text wastes a lot of retrieval signal.
- Users want to query across all of this at once. “Find decisions where a stylized animal logo was rejected for clothing in class 25” needs both a visual concept (animal logo) and structured filters (class 25, rejection outcome).
A pure text pipeline can answer none of these well. So we built two parallel embedding tracks — one for structured text, one for page images — and expose them through separate, purpose-built search modes.
The Corpus
The PoC uses the publicly available trademark decisions (“Marken-Beschwerden”) from the Bundespatentgericht decision database — roughly 15,000 PDF rulings from the trademark appeal senates (24th, 25th, 26th, 27th, 28th, 29th, 30th, 32nd, 33rd Senate). Each PDF is a scanned or natively-generated document containing:
- The court’s reasoning in German legal prose
- The contested mark(s), often as embedded image(s)
- Classification metadata (Nice classes, goods and services lists)
- References to prior case law and statutory provisions
It’s a perfect testbed: large enough to need real retrieval infrastructure, structured enough to benefit from extraction, and visual enough that ignoring the images would defeat the purpose.
Architecture Overview
The system has two parallel embedding tracks during ingestion and separate search modes at query time.
Embedding Pipeline
For each PDF in the corpus, we run two independent extraction paths:
Track 1: Structured JSON extraction
- Document parsing – The PDF is split into pages and the text layer is extracted (with OCR fallback for scanned pages).
- LLM-based structured extraction – A vision-capable LLM reads each decision and emits a JSON object following a fixed schema: docket number, senate, decision date, decision type (rejection / allowance / partial), the marks at issue (word marks, figurative descriptions), Nice classes, cited norms, summary of the legal reasoning, and the outcome.
- Channel-specific text builders – Rather than embedding raw JSON, the extracted data is transformed into purpose-built text representations per retrieval channel (e.g., one focused on word marks, another on figurative element descriptions). Each channel’s text builder composes a natural-language passage from the relevant fields, optimized for what that channel needs to retrieve on.
- Text embedding – Each channel text is embedded with Voyage AI
voyage-3-large, which is multilingual and handles German legal prose well. Multiple embedding vectors per document (one per channel) are stored together.
Track 2: Page-image embedding
- Page rasterization – Each PDF page is rendered to a high-resolution image.
- Vision embedding – Each page image is embedded with Voyage AI
voyage-multimodal-3, a dedicated multimodal embedding model that maps images into a vector space queryable with text. - Vector storage – Image embeddings are stored as an additional column on the same document row, alongside the text-channel embeddings.
Both tracks write into a single PostgreSQL database with pgvector. Each document row in the main table carries multiple embedding columns (one per text channel plus one for the image track), along with the full extracted JSON and metadata.
Query Pipeline
At query time, the system offers separate search modes — text-based and image-based — each optimized for its use case:
Text search (single-channel or multi-channel):
- Query embedding – The user’s query is embedded once with
voyage-3-large. - Multi-channel vector search – The query vector is matched against each requested text-channel embedding column via cosine similarity. Users can weight channels (e.g., emphasize word-mark similarity vs. legal reasoning).
- Weighted score combination – Per-channel similarity scores are combined using a weighted average, giving a single relevance score per document.
- Keyword hybrid boost – A parallel keyword path uses
ILIKEand PostgreSQLpg_trgmtrigram similarity to inject exact-match results that pure vector search might miss, and to boost documents containing the query terms verbatim.
Image search:
- Image embedding – An uploaded image (e.g., a logo) is embedded with
voyage-multimodal-3. - Visual similarity retrieval – The image vector is matched against the image-embedding column to find visually similar marks across the corpus.
Both modes return ranked results with source references — relevant decision pages, extracted metadata, and matching text passages — rather than generating a synthesized answer.
Tech Stack
| Component | Technology |
|---|---|
| LLM (extraction) | OpenAI GPT-5.4-nano |
| Text embeddings | Voyage AI voyage-3-large (multilingual) |
| Image embeddings | Voyage AI voyage-multimodal-3 |
| Vector store | PostgreSQL + pgvector |
| Keyword search | PostgreSQL pg_trgm (trigram similarity) |
| PDF parsing | pymupdf |
| Backend | FastAPI + Uvicorn |
| Language | Python |
Key Takeaways
- Two tracks beat one. Structured text channels give precision and explainability; page images give recall on anything visual the extraction missed. Each covers the other’s blind spots.
- Don’t embed raw JSON. Embedding models are trained on prose, not braces. Channel-specific text builders that compose natural-language passages from extracted fields consistently outperformed embedding raw JSON or simple key-value dumps.
- Schema discipline matters. When the extraction schema drifts across documents, downstream retrieval quality drops noticeably. A strict schema with
nullfor missing fields beats a permissive one. - Multiple embedding channels per document add flexibility. Separating word-mark text from figurative-element descriptions into distinct channels lets users weight what matters for their query. A single monolithic embedding per document loses that control.
- Keyword hybrid search is essential for legal text. Pure vector search misses exact term matches that matter in law (docket numbers, specific mark names). Combining vector similarity with trigram-based keyword matching (
pg_trgm) catches what embeddings alone miss. - Page-level granularity is usually right for visual retrieval. Going finer (regions, figures) adds complexity that didn’t pay off on this corpus; going coarser (whole document) loses the ability to point at the specific page with the contested mark.
- Weighted score combination is simple and effective. For multi-channel retrieval, a weighted average over per-channel cosine similarities is easy to tune and reason about — users can adjust channel weights to shift emphasis between word marks, figurative elements, and legal reasoning.
Outlook
This PoC shows that multimodal search is feasible and useful on a real-world legal corpus. Natural next steps:
- Structured metadata filtering. Adding SQL
WHERE-clause pre-filters on senate, Nice class, date range, and outcome before vector search would dramatically reduce noise for targeted queries. - Cross-modal fusion. Merging text and image results into a single ranked list (e.g., via Reciprocal Rank Fusion) rather than offering separate search modes would give users a unified experience.
- Reranking. Adding a cross-encoder reranker on top of the fused candidate set could improve precision at the top of the result list.
- Active learning on extraction errors. When users flag a wrong answer, tracing back whether the bug was in extraction, retrieval, or generation lets us target re-extraction at the documents that matter.
- Cross-document reasoning. Beyond retrieving single decisions, surfacing how a line of reasoning evolved across senates and years.
The combination of structured extraction and page-image embedding is, in our experience, the most robust foundation for search over visually rich, semi-structured documents — and trademark law happens to be a near-ideal showcase for it.